These days I’m diving deep into the world of LLMs and GPTs, and one curious question popped into my mind:
“How do these models actually understand and generate human-like language?”
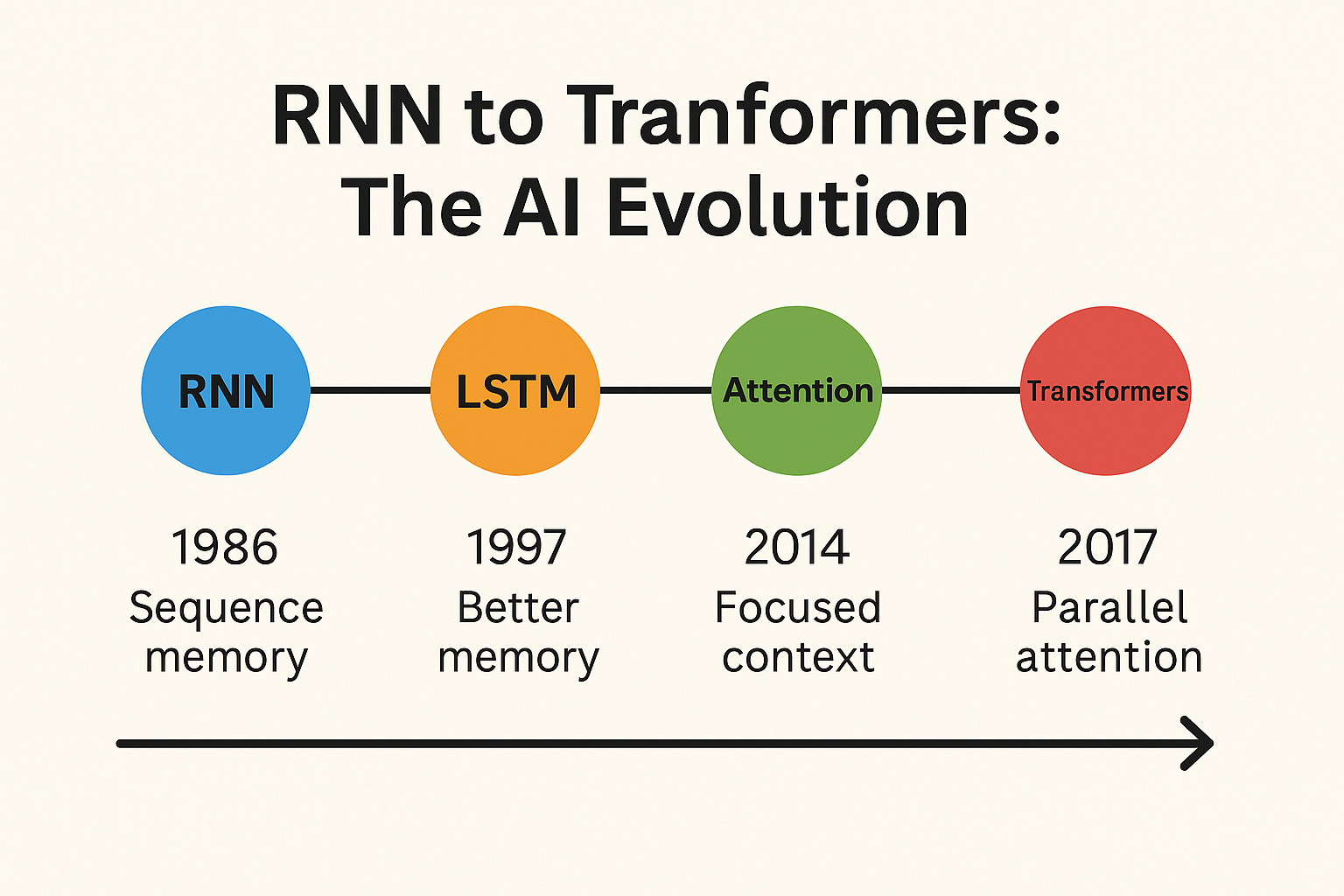
The journey didn’t start just a year ago—it has decades of research behind it. And to really understand it, we need to crack three fundamental concepts: Tokens, Embeddings, and Contextual Understanding.
Let’s break it down with simple, real-world examples
1. What Are Tokens?
A token is the smallest unit that an LLM (like GPT) understands while processing text.
Depending on the tokenizer used, a token could be:
- A word (
apple) - A subword (
ap+ple) - A character (
a,p,p,l,e)
For example, in the sentence: “Unlocking possibilities with AI” GPT might break it down into tokens like:
["Unlock", "ing", " possibilities", " with", " AI"]
This process helps models handle rare words, misspellings, or even entirely new words they’ve never seen before.
2. What Are Embeddings?
Once the text is tokenized, each token is converted into a numerical vector—this is called an embedding.
Think of embeddings as the way models understand “meaning” in mathematical terms.
Example:
Embeddings allow the model to understand:
✅ Similarity between words ✅ Sentiment and tone ✅ Relationships like man:woman :: king:queen
3. What is Embedding Context?
Here’s where it gets exciting!
Let’s look at this sentence:
“He unlocked the bank vault at midnight.”
Now change it to:
“She sat by the river bank to paint the sunset.”
The word “bank” appears in both, but the meaning is totally different.
And yet, it’s the same token!
Contextual embeddings help LLMs like GPT understand that “bank” in sentence one is a financial institution, while in sentence two it refers to the side of a river.
In GPT-style models, every word is processed with attention to what surrounds it. That’s how it captures true meaning, not just definitions.
In Summary

Why This Matters?
When you ask a question to ChatGPT, here’s what happens:
- Your sentence gets tokenized
- Each token is embedded into a numerical format
- The model analyzes the full sentence to understand the context
- It then predicts the next word, one by one — like a brilliant guesser, fine-tuned by billions of examples.
Still curious how these pieces come together when generating text? I’m diving deeper every day—feel free to follow for more such bite-sized breakdowns.
Stay tuned…
#LLM #GPT #AIExplained #MachineLearning #Tokenization #Embeddings #ContextualAI #ArtificialIntelligence #TechSimplified #DeepLearning #NaturalLanguageProcessing